Nginx has a built-in module limit_req for rate-limiting requests, which does a decent job, except its documentation is not known for its conciseness, plus a few questionable design choices. I happen to have a specific need for this feature so I examined it a bit.
As always, everything begins with the documentation. A quick-start example is given:
http {
limit_req_zone $binary_remote_addr zone=one:10m rate=1r/s;
...
server {
...
location /search/ {
limit_req zone=one burst=5;
}
The basis is the limit_req_zone directive, which defines a shared memory zone for storing the states of the rate-limiting. Its arguments include the key, the size and the name of the zone, followed by the average or sustained rate limit. The rate limit has two possible units: r/s or r/m. It also says
The limitation is done using the “leaky bucket” method.
So far so good, except the burst limit is … specified on where it’s used? Moving on for now.
The limit_req directive specifies when the requests should be limited.
If the requests rate exceeds the rate configured for a zone, their processing is delayed such that requests are processed at a defined rate.
Seems pretty clear but slightly counter-intuitive. By default, burst requests are queued up and delayed until the rate is below the limit, whereas most common rate-limiting implementations would simply serve them.
I find it easier to understand this model with a queue. Each key defines a queue where items are popped at the specified rate (e.g. 1r/s). Incoming requests are added to the queue, and are only served upon exiting the queue. The queue size is defined by the burst limit, and excess requests are dropped when the queue is full.
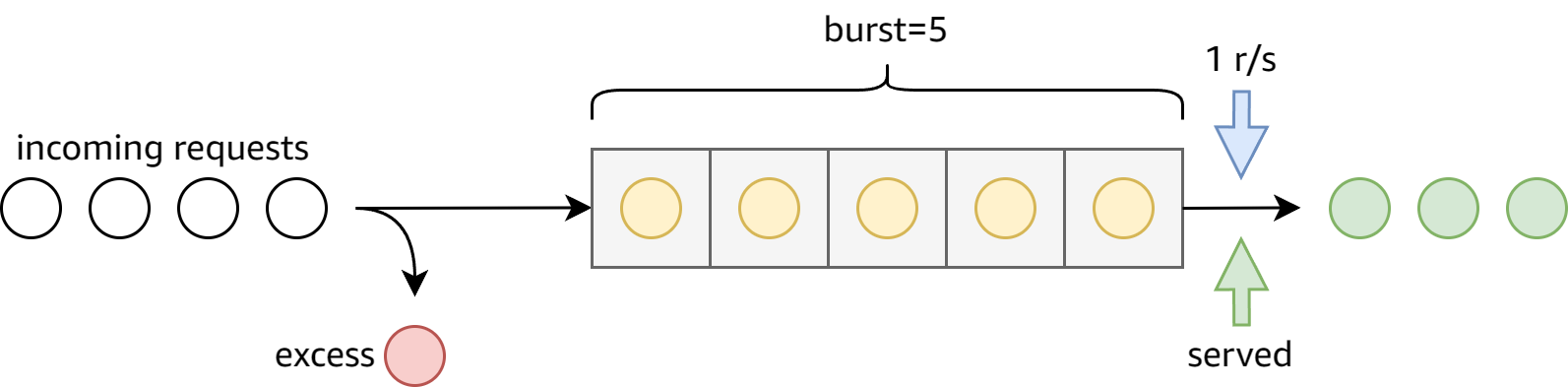
The more common behavior, however, requires an extra option:
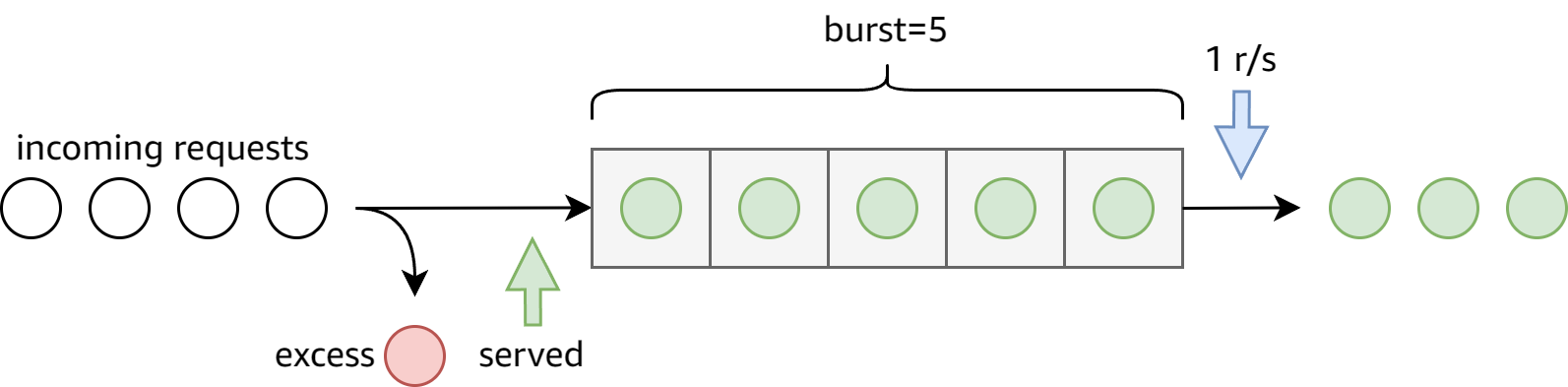
If delaying of excessive requests while requests are being limited is not desired, the parameter
nodelayshould be used:limit_req zone=one burst=5 nodelay;
With nodelay, requests are served as soon as they enter the queue:
The next confusing option, conflicting with nodelay, is delay:
The
delayparameter specifies a limit at which excessive requests become delayed. Default value is zero, i.e. all excessive requests are delayed.
After a bit of fiddling, I realized the model is now like this:
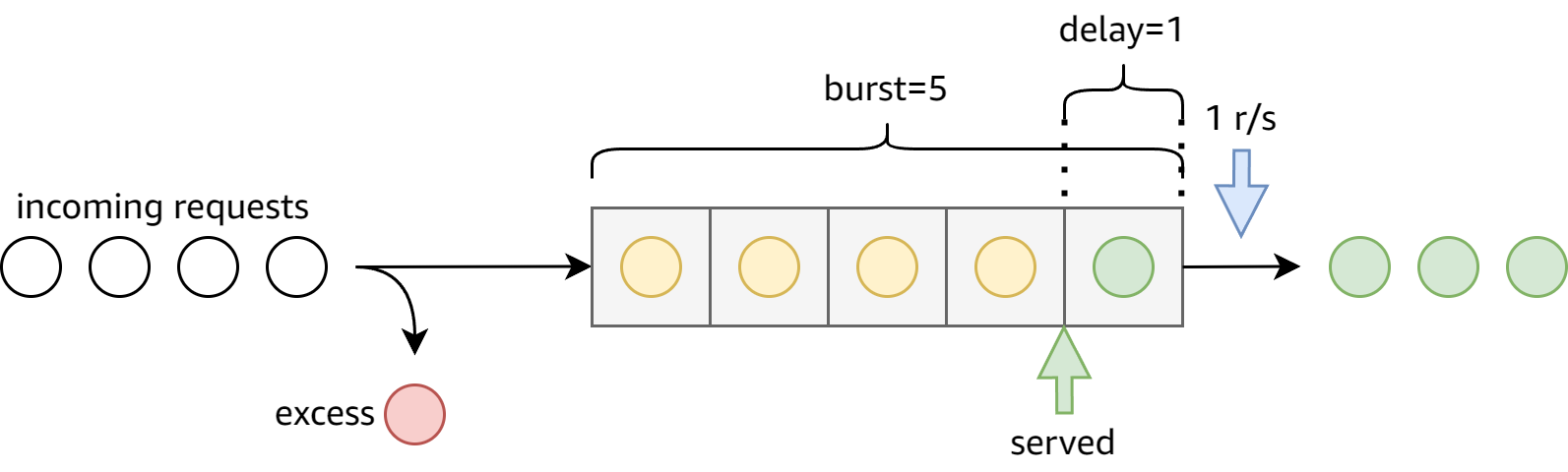
So what delay actually means is to delay requests after this “delay limit” is reached. In other words, requests are served as soon as they arrive at the n-th position in the front of the queue.
During all these testing, I wasn’t happy with existing tools for testing, so I wrote my own one, despite its simplicity: GitHub Gist.
With this new tool, I can now (textually) visualize the behavior of different options. Under the burst=5 and delay=1 setup, the output is like this:
$ go run main.go -i 10ms -c 10 http://localhost/test
[1] Done [0s] [200 in 2ms]
[2] Done [10ms] [200 in 1ms]
[3] Done [21ms] [200 in 981ms]
[4] Done [31ms] [200 in 1.972s]
[5] Done [42ms] [200 in 2.962s]
[6] Done [53ms] [200 in 3.948s]
[7] Done [64ms] [503 in 0s]
[8] Done [75ms] [503 in 1ms]
[9] Done [85ms] [503 in 0s]
[10] Done [95ms] [503 in 0s]
If you try the tool yourself, the HTTP status codes are colored for even better prominence.
In the above example, the first request is served immediately as it also exits the queue immediately. The second request is queued at the front, and because delay=1, it’s also served immediately. Subsequent requests are queued up until the sixth when the queue becomes full. The seventh and thereafter are dropped.
If we change delay=0, the output becomes:
$ go run main.go -i 10ms -c 10 http://localhost/test
[1] Done [0s] [200 in 2ms]
[2] Done [10ms] [200 in 993ms]
[3] Done [21ms] [200 in 1.982s]
[4] Done [32ms] [200 in 2.973s]
[5] Done [43ms] [200 in 3.959s]
[6] Done [54ms] [200 in 4.949s]
[7] Done [65ms] [503 in 1ms]
[8] Done [75ms] [503 in 1ms]
[9] Done [85ms] [503 in 2ms]
[10] Done [96ms] [503 in 1ms]
Still only the first 6 requests are served, but the 2nd to the 6th are delayed by an additional second due to the removal of delay=1.
Under this model, the nodelay option can be understood as delay=infinity, while still respecting the burst limit.
One more question
Why is the burst limit specified at use time, instead of at zone definition? Only experiments can find out:
location /a {
limit_req zone=test burst=1;
}
location /b {
limit_req zone=test burst=5;
}
Then I fire up two simultaneous batches of 10 requests each to /a and /b respectively:
$ go run main.go -i 10ms -c 10 http://localhost/a
[1] Done [0s] [200 in 2ms]
[2] Done [10ms] [200 in 992ms]
[3] Done [21ms] [503 in 0s]
[4] Done [32ms] [503 in 0s]
[5] Done [42ms] [503 in 0s]
[6] Done [53ms] [503 in 0s]
[7] Done [63ms] [503 in 0s]
[8] Done [73ms] [503 in 0s]
[9] Done [83ms] [503 in 0s]
[10] Done [94ms] [503 in 0s]
$ go run main.go -i 10ms -c 10 http://localhost/b
[1] Done [0s] [200 in 1.862s]
[2] Done [11ms] [200 in 2.852s]
[3] Done [21ms] [200 in 3.842s]
[4] Done [32ms] [200 in 4.832s]
[5] Done [43ms] [503 in 1ms]
[6] Done [54ms] [503 in 0s]
[7] Done [64ms] [503 in 0s]
[8] Done [75ms] [503 in 1ms]
[9] Done [85ms] [503 in 0s]
[10] Done [95ms] [503 in 1ms]
As can be seen from the output, the batch to /a is served as usual, but the batch to /b is significantly delayed, and two fewer requests are served.
If I reverse the order of sending the batches, the result is different again:
$ go run main.go -i 10ms -c 10 http://localhost/b
[1] Done [0s] [200 in 2ms]
[2] Done [10ms] [200 in 993ms]
[3] Done [20ms] [200 in 1.982s]
[4] Done [31ms] [200 in 2.974s]
[5] Done [42ms] [200 in 3.963s]
[6] Done [52ms] [200 in 4.955s]
[7] Done [63ms] [503 in 0s]
[8] Done [74ms] [503 in 0s]
[9] Done [84ms] [503 in 0s]
[10] Done [95ms] [503 in 0s]
$ go run main.go -i 10ms -c 10 http://localhost/a
[1] Done [0s] [503 in 1ms]
[2] Done [10ms] [503 in 1ms]
[3] Done [20ms] [503 in 0s]
[4] Done [31ms] [503 in 0s]
[5] Done [42ms] [503 in 0s]
[6] Done [52ms] [503 in 0s]
[7] Done [63ms] [503 in 1ms]
[8] Done [73ms] [503 in 0s]
[9] Done [83ms] [503 in 0s]
[10] Done [93ms] [503 in 0s]
This time the batch to /b is served as usual, but the entire batch to /a is rejected.
I am now convinced that the queue itself is shared between /a and /b, and each limit_req directive decides for itself whether and when to serve the requests. So when /a is served first, the queue holds one burst request, and /b fills the queue up to 5 requests. When /b is served first, the queue is already holding 5 requests and leaves no room for /a. Similarly, with the delay option, each limit_req directive can still decide when the request is ready to serve.
This is probably not the most straightforward design, and I can’t come up with a use case for this behavior. But at least now I understand how it works.
One last thing
I originally wanted to set up a 403 page for banned clients, and wanted to limit the rate of log writing in case of an influx of requests. The limit_req module does provide a $limit_req_status variable which appears to be useful. This is what I ended up with:
limit_req_zone $binary_remote_addr zone=403:64k rate=1r/s;
map $limit_req_status $loggable_403 {
default 0;
PASSED 1;
DELAYED 1;
DELAYED_DRY_RUN 1;
}
server {
access_log /var/log/nginx/403/access.log main if=$loggable_403;
error_log /var/log/nginx/403/error.log warn;
error_page 403 /403.html;
error_page 404 =403 /403.html;
limit_req zone=403;
limit_req_status 403;
limit_req_log_level info;
location / {
return 403;
}
location = /403.html {
internal;
root /srv/nginx;
sub_filter "%remote_addr%" "$remote_addr";
sub_filter_once off;
}
}
With this setup, excessive requests are rejected by limit_req with a 403 status. Only 1r/s passes through the rate limiting, which will carry the PASSED status and be logged, albeit still seeing the 403 page from the return 403 rule. This does exactly what I want, so time to call it a day.



Leave a comment