ZFS is about the most complex filesystem for single-node storage servers. Coming with its sophistication is its equally confusing “block size”, which is normally self-evident on common filesystems like ext4 (or more primitively, FAT). The enigma continues as ZFS bundles more optimizations, either for performance or in the name of “intuition” (which I would hardly agree). So recently I read a lot of materials on this and try to make sense of it.
We’ll begin with a slide from a ZFS talk from Lustre1 (page 5):
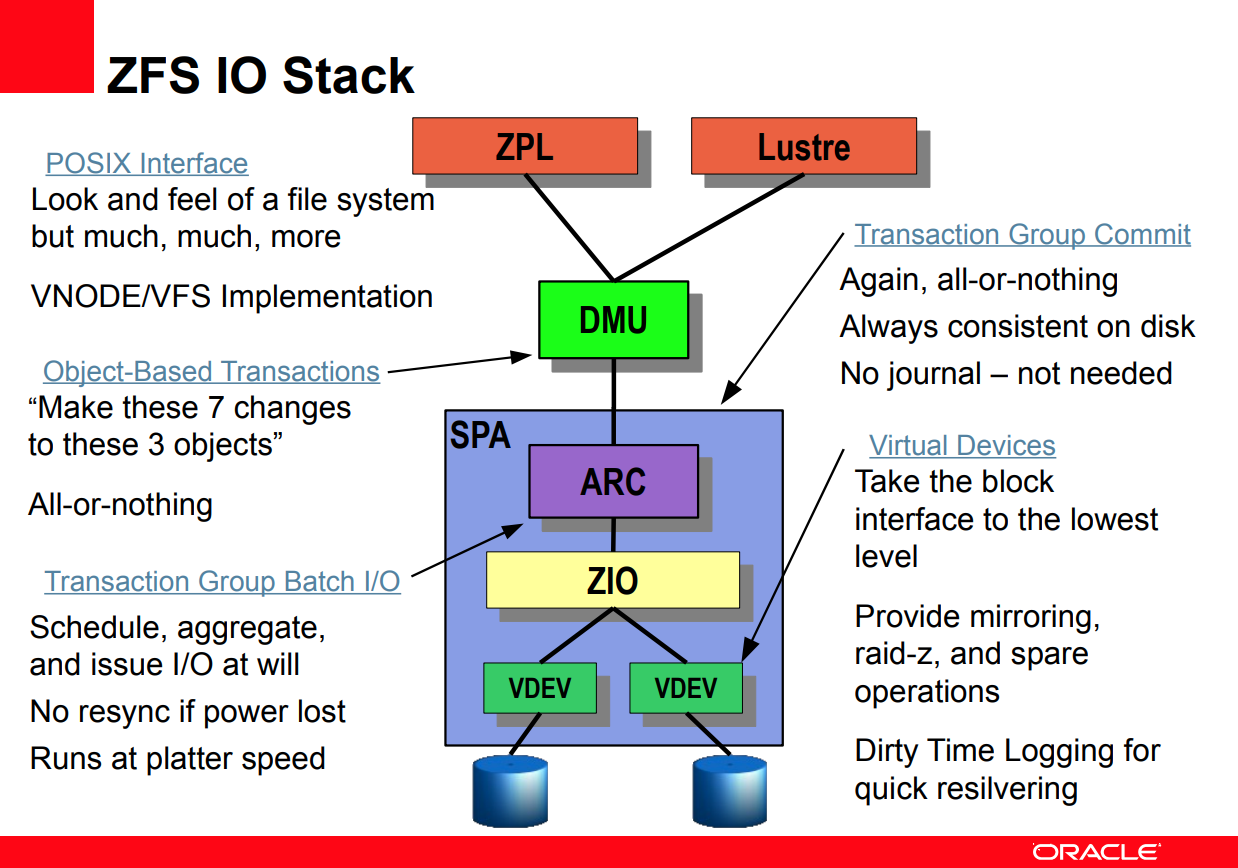
Logical blocks
The first thing to understand is that there are at least two levels of “block” concepts in ZFS. There’s “logical blocks” on an upper layer (DMU), and “physical blocks” on a lower layer (vdev). The latter is easier to understand and it’s almost synonymous to “disk sectors”. It’s precisely the ashift parameter in zpool create command and usually matches the physical sector size of your disks (4 KiB for modern disks). Once set, ashift is immutable and can only be changed when recreating the entire vdev array (fortunately not the entire pool2). The “logical block”, however, is slightly more complicated, and beyond the expressibility of a few words. In short, it’s the smallest meaningful unit of data that ZFS can operate on, including reading, writing, checksumming, compression and deduplication.
“recordsize” and “volblocksize”
You’ve probably seen recordsize being talked about extensively in ZFS tuning guides3, which is already a great source of confusion. The default recordsize is 128 KiB, which controls the maximum size of a logical block. The actual block size depends on the file you’re writing:
- If the file is smaller than or equal to
recordsize, it’s stored as a single logical block of its size, rounded up to the nearest multiple of 512 bytes. - If the file is larger than
recordsize, it’s split into multiple logical blocks ofrecordsizeeach, with the last block being zero-padded torecordsize.
As with other filesystems, if you change a small portion of a large file, only 128 KiB (or whatever your recordsize is) is rewritten, along with new metadata and checksums. Large recordsize bloats the read/write amplification for random I/O workloads, while small recordsize increases the fragmentation and metadata overhead for large files. Note that ZFS always validates checksums, so every read operation is done on an entire block, even if only a few bytes are requested. So it is important to align your recordsize with your workload, like using 16 KiB for (most) databases and 1 MiB for media files. The default 128 KiB is a good compromise for general-purpose workloads, and there certainly isn’t a one-size-fits-all solution. Also note that while recordsize can be changed on the fly, it only affects newly written data, and existing ones stay intact.
For ZVOLs, as you’d imagine, the rule is much simpler: Every block of volblocksize is a logical block, and it’s aligned to its own size. Since ZFS 2.2, the default volblocksize is 16 KiB, providing a good balance between performance and compatibility.
Compression
Compression is applied on a per-block basis, and compressed data is not shared between blocks. This is best shown with an example:
$ zfs get compression tank/test
NAME PROPERTY VALUE SOURCE
tank/test compression zstd inherited from tank
$ head -c 131072 /dev/urandom > 128k
$ cat 128k 128k 128k 128k 128k 128k 128k 128k > 1m
$ du -sh 128k 1m
129K 128k
1.1M 1m
$ head -c 16384 /dev/urandom > 16k
$ cat 16k 16k 16k 16k 16k 16k 16k 16k > 128k1
$ cat 128k1 128k1 128k1 128k1 128k1 128k1 128k1 128k1 > 1m1
$ du -sh 16k 128k1 1m1
17K 16k
21K 128k1
169K 1m1
As you can see from du’s output above, despite containing 8 identical copies of the same 128 KiB random data, the 1 MiB file gains precisely nothing from compression, as each 128 KiB block is compressed individually. The other test of combining 8 copies of 16 KiB random data into one 128 KiB file shows positive results, as the 128 KiB file is only 21 KiB in size. Similarly, the 1 MiB file that contains 64 exact copies of the same 16 KiB chunk is exactly 8 times the size of that 128 KiB file, because the chunk data is not shared across 128 KiB boundaries.
This brings up an interesting point: It’s beneficial to turn on compression even for filesystems with uncompressible data4. One direct impact is on the last block of a large file, where its zero-filled bytes up to recordsize compress very well. Using LZ4 or ZSTD, compression should have negligible impact on any reasonably modern CPU and reasonably sized disks.
There are two more noteworthy points about compression, both from man zfsprops.7:
-
When any setting except off is selected, compression will explicitly check for blocks consisting of only zeroes (the NUL byte). When a zero-filled block is detected, it is stored as a hole and not compressed using the indicated compression algorithm.
Instead of compressing entire blocks of zeroes like the last block of a large file, ZFS will not store anything about these zero blocks. Technically, this is done by omitting the corresponding ranges from the file’s indirect blocks4.
Take this test for example: I created a file with 64 KiB of urandom, then 256 KiB of zeroes, then another 64 KiB of urandom. The file is 384 KiB in size, but only 128 KiB is actually stored on disk:
# zfs create pool0/srv/test # cat <(head -c 64K /dev/urandom) <(head -c 256K /dev/zero) <(head -c 64K /dev/urandom) > /srv/test/test # du -sh /srv/test/test 145K /srv/test/testWe can also examine the file’s indirect blocks with
zdb:# ls -li /srv/test/test 2 -rw-r--r-- 1 root root 393216 Oct 30 02:05 /srv/test/test # zdb -ddddd pool0/srv/test 2 [...] Indirect blocks: 0 L1 0:1791b7d3000:1000 20000L/1000P F=2 B=9769680/9769680 cksum=[...] 0 L0 0:1791b7b1000:11000 20000L/11000P F=1 B=9769680/9769680 cksum=[...] 40000 L0 0:1791b7c2000:11000 20000L/11000P F=1 B=9769680/9769680 cksum=[...] segment [0000000000000000, 0000000000020000) size 128K segment [0000000000040000, 0000000000060000) size 128KHere we can see only two L0 blocks allocated, each being 20000 (hex, dec = 131072) bytes logical and 11000 (hex, dec = 69632) bytes physical in size. The two L0 blocks match the two segments shown at the bottom, with the middle segment nowhere to be found.
-
Any block being compressed must be no larger than 7/8 of its original size after compression, otherwise the compression will not be considered worthwhile and the block saved uncompressed. […] for example, 8 KiB blocks on disks with 4 KiB disk sectors must compress to 1/2 or less of their original size.
This one should be self-explanatory.
RAIDZ
Up until now we’ve only talked about logical blocks, which are all on the higher layers of the ZFS hierarchy. RAIDZ is where physical blocks (disk sectors) really come into play and adds another field of confusion.
Unlike traditional RAID 5/6/7(?) that combine disks into an array and presents a single volume for the filesystem, RAIDZ handles each logical block separately. I’ll cite this illustration from Delphix5 to explain:

This example shows a 5-wide RAID-Z1 setup.
- A single-sector block takes another sector for parity, like the dark red block on row 3.
-
Multi-sector blocks are striped across disks, with parity sectors inserted every 4 sectors, matching the data-to-parity ratio of the vdev array.
- You may have noticed that parity sectors for the same block are always stored on the same disk that resembles RAID-4 instead of RAID-5. Keep in mind that ZFS reads, writes and verifies entire blocks, so interleaving parity sectors across disks will not provide any benefit, while keeping “stripes” on the same disk simplifies the logic for validation and reconstruction.
- In order to avoid unusable fragments, ZFS requires each allocated block to be padded to a multiple of (p+1) sectors, where p is the number of parity disks. For example, RAID-Z1 requires each block to be padded to a multiple of 2 sectors, and RAID-Z2 requires each block to be padded to a multiple of 3 sectors. This can be seen on rows 7 to 9, where the X sectors are reserved for parity padding.
This design allows RAID to play well with ZFS’s log-structured design and avoids the need for read-modify-write cycles. Consequently, the RAID overhead is now dependent on your data and is no longer an intrinsic property of the RAID level and array width. The same Delphix article shares a nice spreadsheet6 that calculates RAID overhead for you:
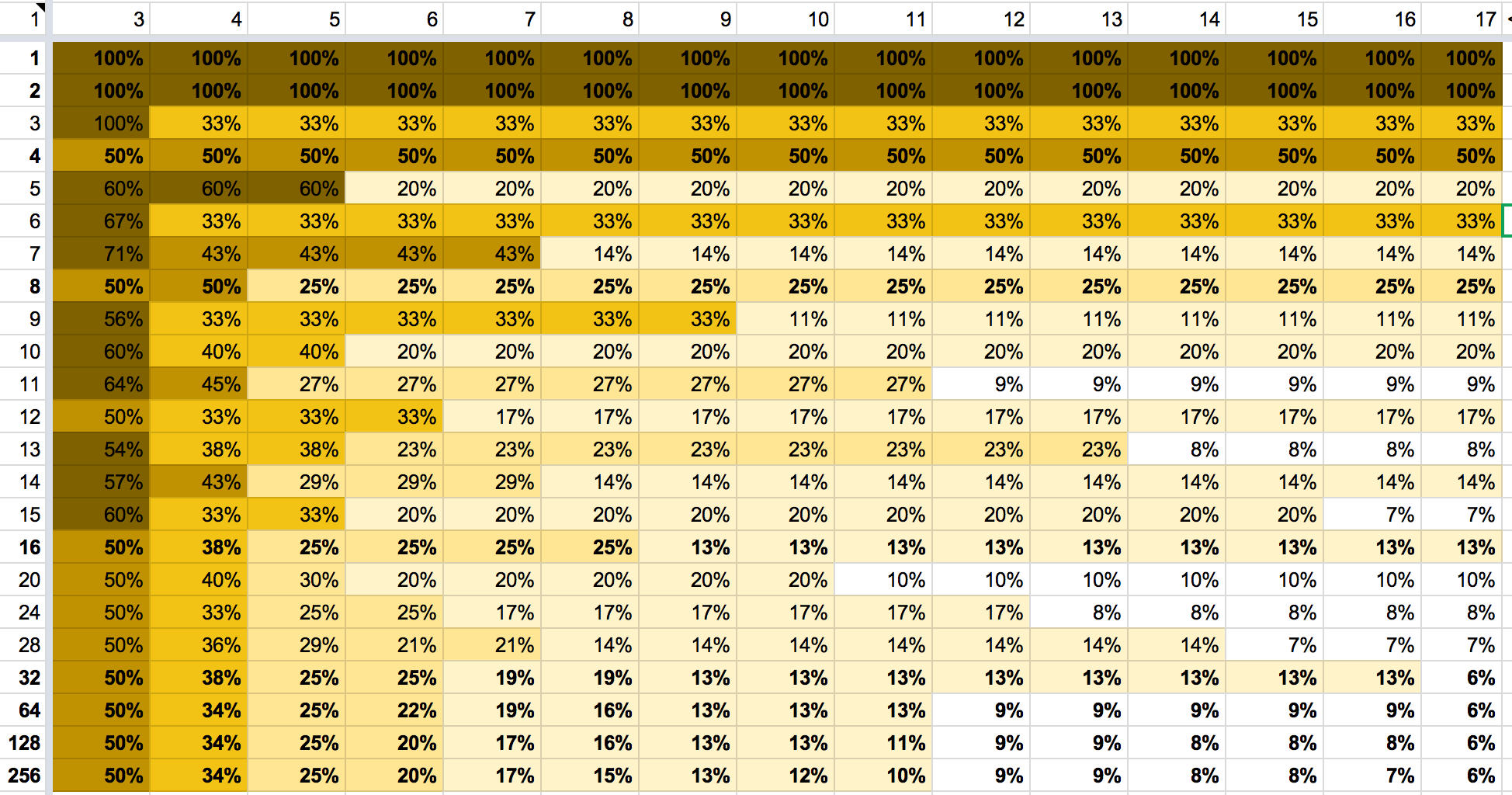
Accounting
Accounting the storage space for a RAIDZ array is as problematic as it seems: There’s no way to calculate the available space in advance without knowledge on the block size pattern.
ZFS works around this by showing an estimate, assuming all data were stored as 128 KiB blocks7. On my test setup with five 16 GiB disks in RAID-Z1 and ashift=12, the available space shows as 61.5G, while zpool shows the raw size as 79.5G:
# zpool create -o ashift=12 test raidz1 nvme3n1p{1,2,3,4,5}
# zfs list test
NAME USED AVAIL REFER MOUNTPOINT
test 614K 61.5G 153K /test
# zpool list test
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
test 79.5G 768K 79.5G - - 0% 0% 1.00x ONLINE -
When I increase ashift to 15 (32 KiB sectors), the available space drops quite a bit, even if zpool shows the same raw size:
# zpool create -o ashift=15 test raidz1 nvme3n1p{1,2,3,4,5}
# zfs list test
NAME USED AVAIL REFER MOUNTPOINT
test 4.00M 51.3G 1023K /test
# zpool list test
NAME SIZE ALLOC FREE CKPOINT EXPANDSZ FRAG CAP DEDUP HEALTH ALTROOT
test 79.5G 7.31M 79.5G - - 0% 0% 1.00x ONLINE -
In both cases, calculating the “raw” disk space from the available space gives roughly congruent results:
- 61.5 GiB × (1 + 25%) = 76.9 GiB
- 51.3 GiB × (1 + 50%) = 76.9 GiB
The default refreservation for non-sparse ZVOLs exhibits a similar behavior:
# zfs create -V 4G -o volblocksize=8K test/v8k
# zfs create -V 4G -o volblocksize=16K test/v16k
# zfs get refreservation test/v8k test/v16k
NAME PROPERTY VALUE SOURCE
test/v16k refreservation 4.86G local
test/v8k refreservation 6.53G local
Interestingly, neither of the refreservation sizes matches the RAID overhead as calculated in the Delphix spreadsheet6, as you would expect some 6.0 GiB for the 16k-volblocksized ZVOL and some 8.0 GiB for the 8k-volblocksized one. Let’s just don’t forget that the whole accounting system assumed 128 KiB blocks and scaled by that8. So the actual meaning of 4.86G and 6.53G would be “the equivalent space if volblocksize had been 128 KiB”. If we multiply both values by 1.25 (overhead for 128 KiB blocks and 5-wide RAIDZ), we get 6.08 GiB and 8.16 GiB of raw disk spaces respectively, both of which match more closely the expected values. The final minor difference is due to the different amount of metadata required for different number of blocks.
Thoughts
I never imagined I would delve this deep into ZFS when I first stumbled upon the question. There are lots of good write-ups on individual components of ZFS all around the web, and Chris Siebenmann’s blog in particular. But few combine all the pieces together and paint the whole picture, so I had to spend some time synthesizing them by myself. As you’ve seen in the Luster slide, ZFS is so complex a beast that it’s hard to digest in its entirety. So for now I have no idea how much effort I would put into learning it, nor any future blogs I would write. But anyways, that’s one large mystery solved, for myself and my readers (you), and time to call it a day.
References
-
Andreas Dilger (2010) ZFS Features & Concepts TOI ↩
-
Jim Salter (2020) ZFS 101 – Understanding ZFS storage and performance ↩
-
OpenZFS Workload Tuning ↩
-
Chris Siebenmann (2017) ZFS’s recordsize, holes in files, and partial blocks ↩ ↩2
-
Matthew Ahrens (2014) How I Learned to Stop Worrying and Love RAIDZ ↩
-
RAID-Z parity cost (Google Sheets) ↩ ↩2
-
openzfs/zfs#4599 (2016) disk usage wrong when using larger recordsize, raidz and ashift=12 ↩
-
Mike Gerdts (2019) (Code comment in
libzfs_dataset.c) ↩


Leave a comment